
Vom Wert der Daten: Datenwertschöpfung in Theorie und Praxis
Daten stellen im betrieblichen Alltag eine ständig wachsende Ressource dar, die kostengünstig verfügbar ist und in vielen Fällen neue Lösungsansätze für bekannte Herausforderungen verspricht. Eine erfolgreiche Datenwertschöpfung erfordert in der Praxis ein strukturiertes, auf die gewünschte Wertschöpfungsform abgestimmtes Vorgehen.
1. Daten in Hülle und Fülle
Daten stellen im betrieblichen Alltag eine allgegenwärtige, ständig wachsende und vergleichsweise kostengünstige Ressource dar. Die voranschreitende Digitalisierung aller Lebensbereiche wird die verfügbare Datenmenge in der näheren Zukunft weiter stark steigen lassen. 1 Ökonomisch ist es daher sinnvoll, die Ressource Daten auch in den wertschöpfenden Unternehmensprozessen einzusetzen.
2. Wertschöpfung durch Daten
Wertschöpfung aus Daten kann sehr unterschiedliche Formen annehmen: Im Sinne einer data economy werden Daten als zentrales Element eines Geschäftsmodells verstanden, während bei data driven-Ansätzen Daten bestehende Geschäftsmodelle unterstützen und ergänzen. Betrachtet man die US-amerikanischen Marktführer Google, Amazon, Facebook, Apple und Microsoft lässt deren Fokus auf das Endkunden-Geschäft ( b2c) die Disruption, also die überraschende Ablöse ganzer Geschäftsmodelle und Märkte, als primäre Form der Datenwertschöpfung vermuten. Im Kontext der für Europa charakteristischen, hochtechnologischen industriellen Produktion und des resultierenden Geschäfts zwischen Unternehmen ( b2b) ergibt sich allerdings ein differenzierteres Bild. Daten werden zur Optimierung bestehender Prozesse verwendet, bilden Grundlage und Hebel für die Lösung beständiger Herausforderungen und werden ihrerseits zum Gegenstand der Monetarisierung.
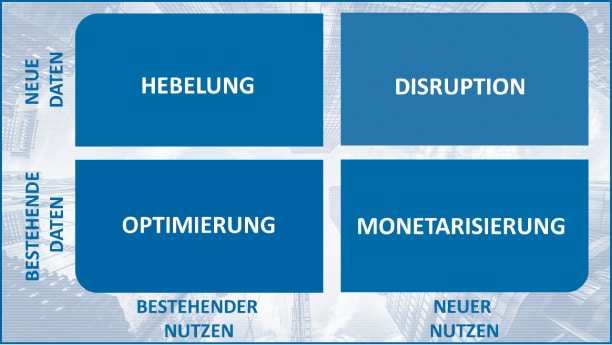
Eine erste Taxonomie der Datenwertschöpfung lässt sich entlang zweier Achsen aufstellen. 2 Zum einen können in einem Wertschöpfungsszenario bestehende Daten oder neue Daten zum Einsatz kommen. Zum anderen können Daten bestehendes Geschäft verbessern oder gänzlich neu genutzt werden. Je nach Kombination ergeben sich vier Varianten der Datenwertschöpfung:
- Die Optimierung verwendet vorhandene Daten zur Verbesserung bereits bestehender Geschäftsprozesse. Anwendungsbeispiele finden sich in den zahlreichen Ansätzen zur Nutzung von Sensor- und Automationsdaten in der produzierenden Industrie, die unter dem Begriff Industrie 4.0 zusammengefasst werden.
- Die Hebelung verwendet neue Daten, um vorhandene Prozesse und Geschäftsmodelle zu verbessern. Prominente Beispiele für diese Art der Datenwertschöpfung finden sich in der Nutzung neuer Kundendaten im Marketing oder in der Optimierung der Transportlogistik durch Berücksichtigung öffentlich verfügbarer Daten.
- Eine Monetarisierung von Daten liegt vor, wenn mit bestehenden Daten neue Formen der Wertschöpfung aufgebaut werden können. Monetarisierung findet sich quer durch alle Geschäftsbereiche: Als Beispiel sei ein Botendienst genannt, der die Positionsdaten seiner Fahrzeuge zur Bestimmung von Staus an Verkehrsnetzbetreiber verkauft.
- Die Disruption durch Daten beschreibt die vollständige Transformation von Märkten und Geschäftsmodellen durch die Verwendung neuer Daten auf neuen Wegen. Beispiele dafür liefert das Endkunden-Geschäft von Unternehmen wie Amazon und Google, die durch ihre Daten-Plattformen rasch neue Wertschöpfungsmodelle implementieren können.
3. Datenwert in der Praxis
Für eine erfolgreiche Datenwertschöpfung in der Praxis muss sich das Verhältnis zwischen Datenwert und Aufwand der Datennutzung zumindest die Waage halten. Entsprechende Aufwände lassen sich anhand des Standard-Prozesses CRIPS-DM und des von IBM 2015 veröffentlichten Nachfolge-Standards ASUM-DM 3 recht genau bestimmen. Der Datenwert dagegen ist stark abhängig vom konkreten Anwendungsfall. In der Folge sollen zwei Beispiele die Datenwertschöpfung in der Praxis illustrieren. Darüber hinaus betrachten wir einen Prozess zur Prüfung des Datenwert-Potentials in Unternehmen.

3.1. Datengetriebene Inventur
Produzierende Unternehmen legen großen Wert auf die regelmäßige und korrekte Inventur aller in der Produktion verwendeten Teile und Materialien. Unregelmäßigkeiten in der Inventur wirken sich direkt auf das Verhältnis zwischen Investitionsausgaben ( capex) und Betriebskosten ( opex) aus und stehen darum im Zentrum der Aufmerksamkeit. Bei der Herstellung eines Fahrzeugs werden beispielsweise rund 30.000 Teile in mehreren räumlich getrennten Montagewerken verbaut. Eine bis ins Detail korrekte Inventur ist in diesem Fall keine triviale Aufgabe.
Im Rahmen eines Projektes mit einem großen österreichischen Fahrzeugbauer, wurden mehrere 100 Millionen Transaktionen aus Lager und Disposition datentechnisch aufbereitet. Gemeinsam mit Schlüsselpersonen im Unternehmen wurden Hypothesen zu Phänomenen in der Inventur entwickelt. Eine Hypothese war zum Beispiel, dass sich die Anzahl von Inventurfehlern unmittelbar nach Wochenenden erhöht. Die Hypothesen wurden datengetrieben bestätigt oder verworfen und die Ergebnisse wurden durch entsprechende Daten untermauert. So konnten weit jenseits der in Data-Warehouses verfügbaren KPIs konkrete Anhaltspunkte für Erfolgsfaktoren zur korrekten Inventur identifiziert und das Inventurergebnis signifikant verbessert werden. Charakteristisch für eine solche Datenwertschöpfung durch Optimierung ist die Nutzung vorhandener, jedoch bisher aufgrund technischer Hürden brachliegender Datenbestände.
3.2. Datengetriebene Risikobewertung
Kreditversicherer stehen vor der Aufgabe, sich ein möglichst aktuelles und genaues Bild von der Risikolage ihrer Kunden zu machen. Im Unternehmensbereich sind sie dabei traditionell auf Bilanzdaten und andere finanzielle Indikatoren angewiesen, die oft mehrere Monate alt sind und ein unvollständiges Bild des Unternehmenszustandes zeichnen. Öffentlich verfügbare Informationen über Unternehmen und deren zentrale Akteure, wie sie etwa in Wirtschaftsnachrichten enthalten sind, finden dagegen nur unstrukturiert und anlassbasiert Eingang in die entsprechenden Bewertungen.
Im Rahmen eines Projektes mit einer großen internationalen Kreditversicherung wurden zahlreiche Online-Nachrichtenquellen erschlossen und automatisch nach Nachrichten durchsucht, welche sich mit den Versicherungskunden beschäftigen. Gefundene Nachrichten wurden automatisch hinsichtlich ihrer Relevanz für die Unternehmensbewertung kategorisiert und, falls eine Auswirkung auf die Kreditwürdigkeit möglich ist, den entsprechenden Kundenbetreuern zur Berücksichtigung vorgelegt. Durch diese Hebelung mit Hilfe neuer, externer und bislang ungenutzter Daten, konnte ein alternativer Ansatz für die Risikobewertung geschaffen werden. Diese Herangehensweise ergänzt traditionelle Prozesse, ersetzt sie aber nicht.
3.3. Datenwertbestimmung in der Praxis
Eine Bestimmung des Datenwerts, eine Datenwertprüfung, ist angesichts der vielen Facetten der Datennutzung in Anwendungsfällen eine wesentliche Voraussetzung und erster Schritt auf dem Weg zur Wertschöpfung aus Daten. Am Know-Center, einem der führenden europäischen Forschungszentren für Data-driven-Business und Artificial Intelligence, wurde dazu ein strukturierter Ansatz unter dem Überbegriff „Data Value Check“ entwickelt. 4
Der Data-Value-Check dient der Generierung und Auswahl erfolgversprechender datengetriebener Use-Cases auf Basis einer Kosten-Nutzen-Logik. Um das Nutzenpotenzial von Daten zu evaluieren, ist es notwendig, neben technischen auch wirtschaftliche und rechtliche Einflussfaktoren (DSGVO, Urheberrechte usw) zu berücksichtigen. Da insbesondere die Einschätzung der Dateneignung eine verhältnismäßig aufwändige Aufgabe darstellt, müssen weniger erfolgversprechende, zu risikoreiche oder schlichtweg unmögliche Use-Cases möglichst früh identifiziert und verworfen werden, um einen effizienten Ablauf zu garantieren.
4. Die Zukunft: Vertrauen und Kontrolle
Vertrauen in die zugrundeliegenden Daten und Analyseverfahren sowie Kontrollmöglichkeiten sind eine wesentliche Voraussetzung zur Umsetzung von Wertschöpfung aus Daten. Leider sind viele der in der Datenwissenschaft verwendeten Verfahren sogenannte black box models, die zwar analytische Aussagen treffen, diese jedoch nicht belegen und argumentieren können und deren Entscheidungswege für Menschen nicht nachvollziehbar sind. Zahlreiche Forschungsinitiativen, darunter das am Know-Center laufende COMET-Modul „DDAI – Privacy Preserving Data Driven Artificial Intelligence“ 5 beschäftigen sich damit, sichere, verifizierbare und erklärbare KI, die gleichzeitig die Privatsphäre schützt, zu entwickeln. Das DDAI-Modul ermöglicht Unternehmen den Austausch von vertraulichen Daten für Analysezwecke und schafft so die Grundlage für eine Plattformökonomie in der europäischen Industrie. Das Modul umfasst damit alle Stationen der Datenverarbeitungskette, von der zu verifizierenden Datenquelle, über kryptographische Verfahren zur sicheren Datenverarbeitung und bietet Nutzern der AI eine bessere, weil nachvollziehbarere, Entscheidungsgrundlage.
Die unternehmerische Wertschöpfung der nahen Zukunft wird zu einem guten Teil datengetrieben erfolgen und auf Methoden basieren, denen wir aufgrund fortgeschrittener Verschlüsselungsverfahren vertrauen und deren Entscheidungen wir im Zweifelsfall prüfen und nachvollziehen können.
Der Beitrag ist in CFOaktuell (Heft 2/2021) erschienen. Mehr Infos unter: www.cfoaktuell.at
Weiterbildungstipps:
Certified Business Data Scientist | Wettbewerbsvorteile mit Big Data, Advanced Analytics und Machine Learning | Info und Anmeldung
Certified Business Data Manager | Wertschöpfung durch Datenmanagement – Strategie, Data Governance und Data Driven Business | Info und Anmeldung
Certified Reporting Professional | Steigern Sie die Effektivität und Effizienz Ihres Berichtswesens | Info und Anmeldung

Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlassen Sie uns Ihren Kommentar!