
Forecasting in der Unternehmensplanung
Forecasting und Predictive Modeling, also die Vorhersage zukünftiger Entwicklungen, ist im breiteren Sinn der gesamte Prozess der Planung. Im engeren Sinn, also im Rahmen der Zeitreihenanalyse, bedeutet Forecasting die Schätzung der zukünftigen Werte auf Basis der vergangenen Werte. Letzteres ist ein rein quantitativer Ansatz: Man verwendet historische Daten, sogenannte Zeitreihen, um mithilfe mathematischer und statistischer Verfahren Muster zu erkennen und zu einer Vorhersage zu gelangen.
Datengrundlage sind also historische Daten, und man setzt voraus, dass die Muster auch in Zukunft aufrecht bleiben. Warum boomen datengetriebene Prognosemodelle derzeit so? Hier ein paar Antworten darauf:
- Es gibt mittlerweile zu vielen Unternehmensgrößen Daten, die standardisiert in fixen Perioden (Wochen, Monate, Quartale) erfasst wurden: genau das sind Zeitreihen.
- Die Implementierung der Prognosemodelle in Standard-Software schreitet immer weiter voran: in Excel ist etwa das „Prognoseblatt“ erschienen, womit das Erstellen und Validieren von Forecasts mit einigen wenigen Klicks erledigt ist.
- Die mathematischen Modelle sind hoch effizient, automatisierbar, zu 100 Prozent objektiv, und – last but not least – sie sind überprüfbar, und das bereits vor dem Einsatz in der Praxis!
- Die statistischen Verfahren quantifizieren immer, wie genau bzw. ungenau die Vorhersage ist. Man sagt also voraus, was die Zukunft bringt, aber immer unter Angabe der Unsicherheit dabei.
Nun, wie läuft Forecasting also technisch ab? Schematisch betrachtet kann der Prozess wie folgt veranschaulicht werden:
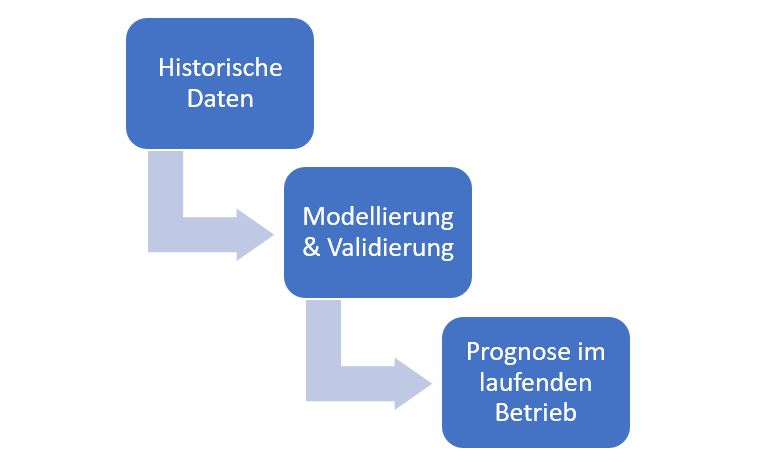
Am Ausgangspunkt steht also die historische Zeitreihe, hier dazu ein Beispiel mit monatlichen Werten zu Umsatz, Kosten und Deckungsbeitrag:
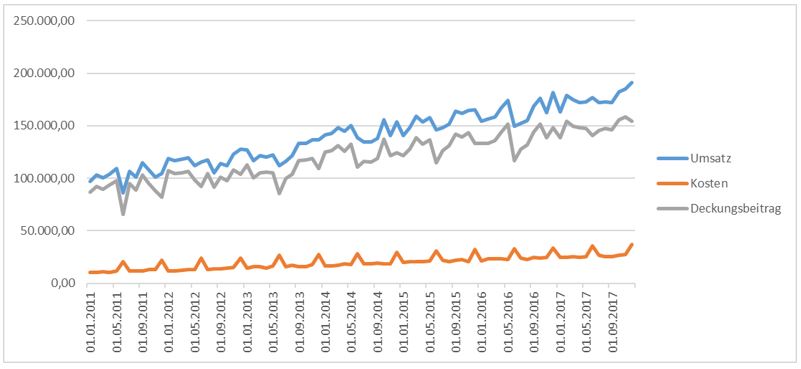
Die Entwicklung der Kosten ist schon mit freiem Auge erkennbar: ein leicht steigender Trend mit regelmäßigen Spitzen nach oben. Über die Regressionsformeln im Excel lässt sich berechnen, was das in Zahlen bedeutet: Die Kosten steigen monatlich konstant um rund 200 Euro an, und alle 6 Monate kommen rund 10.000 zusätzlich dazu. Über die Trendformel kann dann berechnet werden, wie sich die Kosten weiterentwickeln, und über die Trendlinie lässt sich das im Diagramm grafisch darstellen.
Forecasting in Excel
In Excel gibt es die Trendlinie und entsprechende Funktionen dazu. Dabei hat jede Zeitreihe ihre eigene Trendlinie, da sie ja unterschiedlich stark steigen:
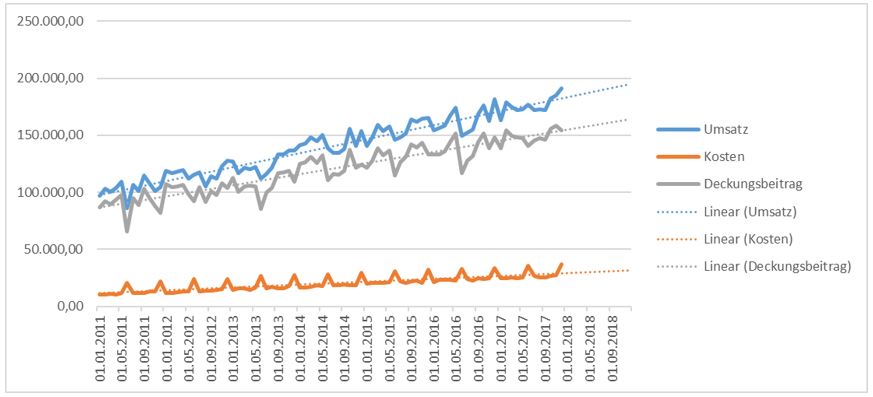
Der lineare Trend als Prognosemodell hat allerdings Grenzen, denn meist gibt es saisonale oder zyklische Schwankungen in den Zeitreihen. Daher der Quantensprung in die neue Funktionalität von Excel: das Prognoseblatt oder Exponential Triple Smoothing (ETS), einfach mit wenigen Klicks zu einem komplexen mathematischen Modell. Markieren Sie die Zeitreihe und klicken im Registerblatt „Daten“ auf „Prognoseblatt erstellen“:
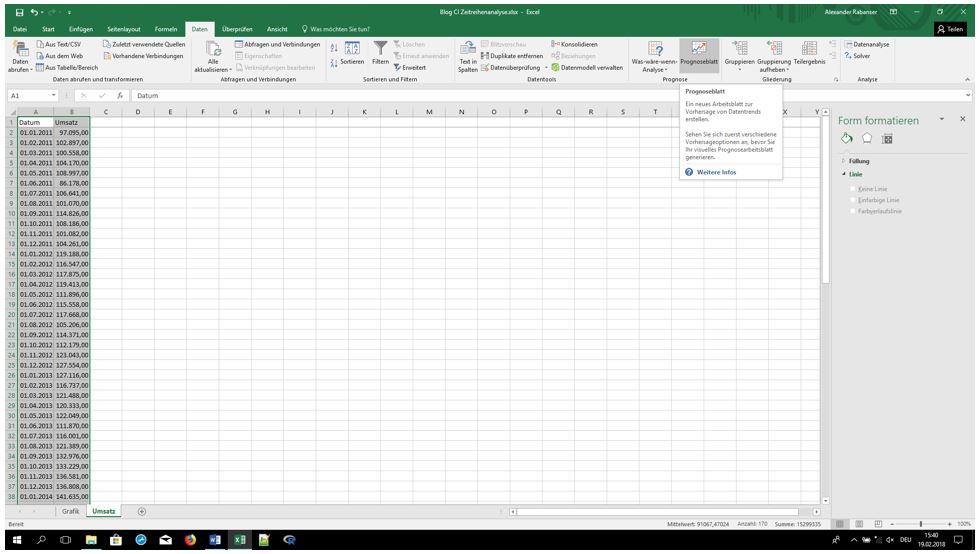
Es öffnet sich ein Pop-up, in dem gleich eine Vorhersage bis Ende 2019 vorgeschlagen wird. Das ist ein guter Horizont: die historischen Daten gehen 7 Jahre zurück, also kann die Prognose ruhig 2 Jahre nach vorne gehen. Es wird ein neues Sheet erzeugt, das die Grafik mit der Prognose enthält, aber auch die gesamte Berechnung und die Formeln dazu:
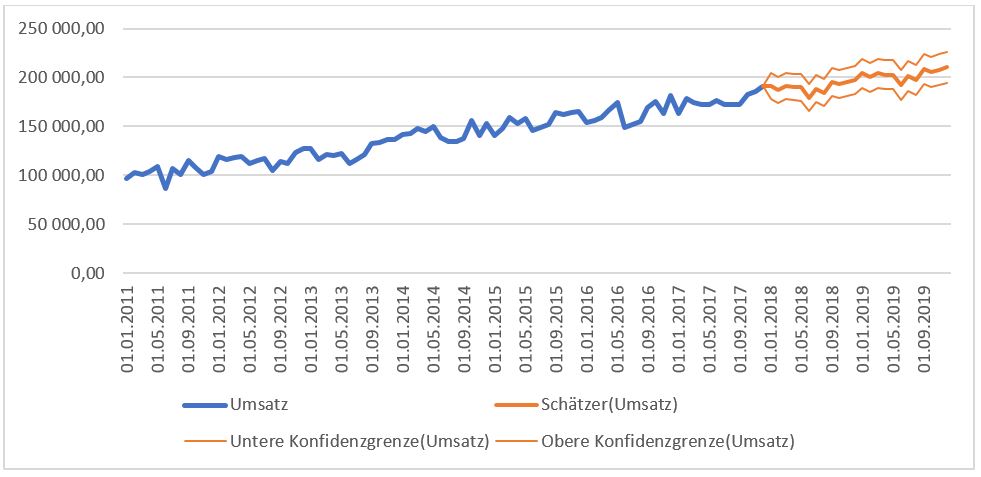
Man erkennt schnell, was der Unterschied zur einfachen linearen Trendlinie ist. Dieses Modell berücksichtigt nämlich nicht nur den linearen Trend, sondern zusätzlich auch noch saisonale Schwankungen und zyklische Schwankungen. Zur Begriffsklärung:
Der lineare Trend ist eine gerade Linie, ganz ohne Schwankungen.
Saisonalitäten sind Schwankungen, die auf einzelne Monate oder Saisonen zurückzuführen sind, wie z.B. schwache Sommermonate von Juni bis August.
Zyklen sind Schwankungen, die nicht auf Saisonen oder einzelne Kalendermonate zurückzuführen sind, die aber dennoch periodisch wiederholend auftretet wie z.B. ein starker Monat immer nach einem schwachen Monat oder umgekehrt.
Aus diesen drei Komponenten setzt sich der Schätzer, also die Prognose zusammen. Im Hintergrund berechnet Excel hier ein komplexes Modell, um die gesamte Information der Daten optimal auszunutzen. Nichtsdestotrotz ist ein mathematisches Modell ist immer bloß eine vereinfachte Darstellung der Realität. Daher gibt es sogenannte Konfidenzintervalle, oder Konfidenzgrenzen. Diese Grenzen beruhen auf statistischen Annahmen, sind jedoch einfach zu interpretieren: mit 95 prozentiger Wahrscheinlichkeit liegt der Umsatz innerhalb der unteren und oberen Grenze.
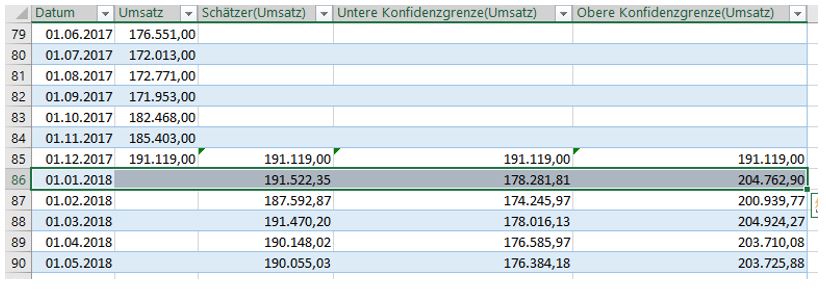 Lesebeispiel: Im Jänner 2018 ist die wahrscheinlichste Höhe für den Umsatz bei 191.552,35 (Schätzer). Im schlechtesten Fall liegt er bei 178.281,81 und im besten Fall bei 204.762,90 (untere / obere Konfidenzgrenze).
Lesebeispiel: Im Jänner 2018 ist die wahrscheinlichste Höhe für den Umsatz bei 191.552,35 (Schätzer). Im schlechtesten Fall liegt er bei 178.281,81 und im besten Fall bei 204.762,90 (untere / obere Konfidenzgrenze).
Nun aber der wichtigste Schritt im Forecasting: das Modell muss validiert werden. Dazu überprüft man, ob das Modell in der Vergangenheit richtig gelegen wäre, also z. B. wenn wir es bereits im Vorjahr eingesetzt hätten. Das ist der größte Vorteil datenbasierter Methoden, sie lassen sich vor dem Einsatz in der Praxis genau überprüfen Das geht in Excel wieder nur mit einigen Klicks: Man erstellt ein neues Prognoseblatt, allerdings mit geändertem Prognosehorizont:
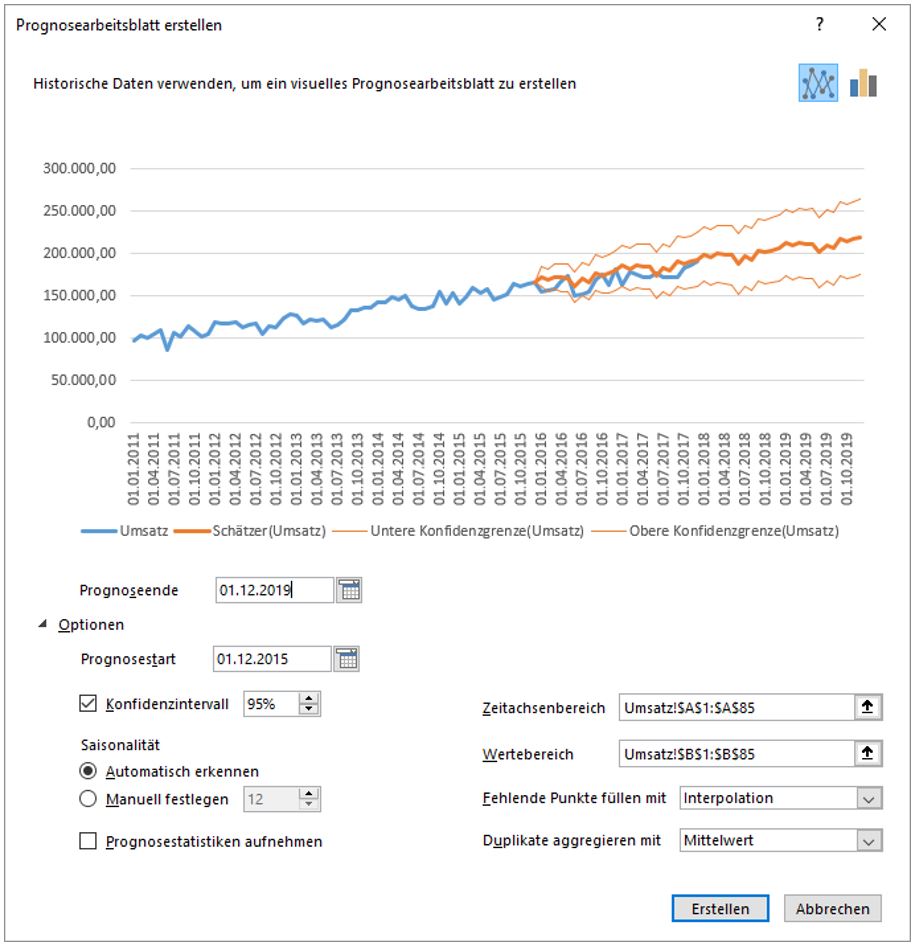
In der Grafik lässt sich erkennen, wie die echten Werte des Vorjahres zur Prognose gepasst haben: Die blaue Linie ist fast immer innerhalb des Konfidenzbereichs. Das Modell hätte also gut funktioniert und ist für den live Einsatz also bereit. Man sieht allerdings auch, dass die Konfidenzbänder immer breiter werden, je weiter der Prognosehorizont voranschreitet. Das ist aber klar: die Umsätze in ferner Zukunft sind mit größerer Unsicherheit behaftet als die in naher Zukunft.
Hier spielt das Verhältnis der Datenmengen eine Rolle: Vergangenheit zu Zukunft sollte in der Größenordnung von 3 zu 1 stehen. Das heißt: aus 3 Jahren Vergangenheit kann 1 Jahr Prognose generiert werden, aber natürlich keine 30 Jahre. Zur Erinnerung: die mathematischen Modelle suchen nach Mustern im zeitlichen Verlauf der Werte, je mehr Daten also vorhanden sind, desto besser.
Time Series Analysis in R
R ist ein kostenloses Tool für statistische Datenanalyse, das bereits in den 90er Jahren gegründet worden ist und sich in den letzten Jahren immer breiterer Beliebtheit erfreut:
R stellt eine gute Erweiterung zu Excel dar, z.B. die Time Series Decomposition, also die Zerlegung der Zeitreihe in Trend und saisonale Schwankungen:
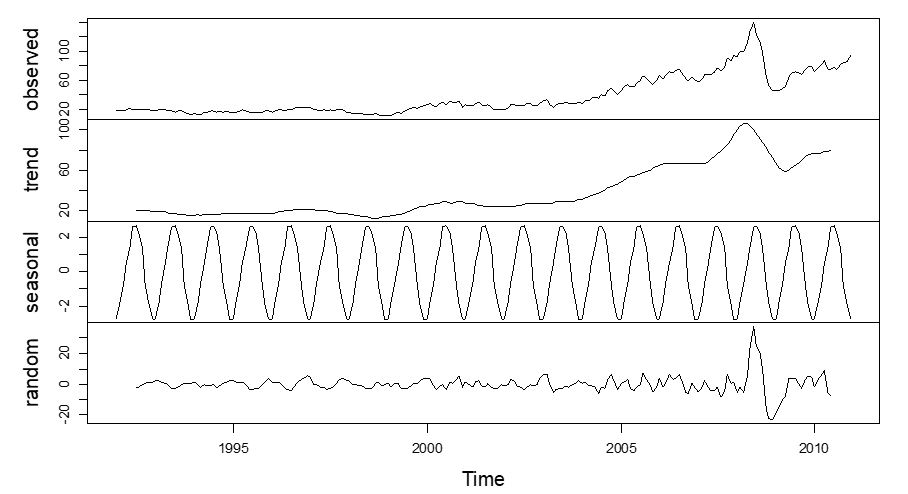
Die erste Reihe zeigen die echten Ölpreise, darunter wird sie zerlegt in einen Trend und saisonale Schwankungen. Die letzte Reihe ist der Zufallsfehler, das ist die übrig bleibende Abweichung zu den echten Werten. In R lässt sich nun automatisch ein Forecast berechnen, der Trend, Saisonalitäten und zufällige Abweichungen berücksichtigt:
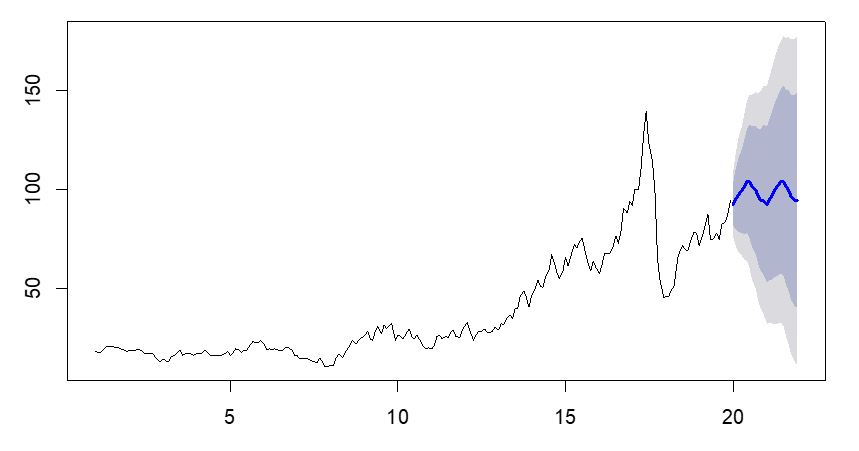
Die Konfidenzbänder sind hier sehr breit, d.h. es kann zu einem starken Preisrückgang kommen, aber auch zu einem starken Anstieg. Nun, das ist ein typisches Beispiel für ein Modell, das zu ungenau ist: Rohstoffpreise können erfahrungsgemäß nicht sehr gut vorhergesagt werden, da sie keinen klaren Mustern folgen.
Tipps für die Praxis
Es gibt über die mathematischen Modelle hinaus eine sehr einfache Technik, um einen Aufwärtstrend bzw. Abwärtstrend zu beschreiben: der Moving Average (gleitender Durchschnitt).
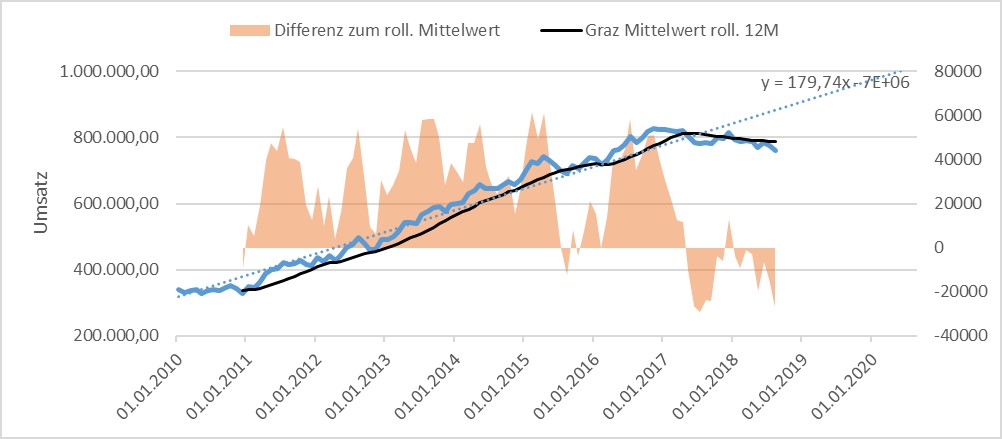
Die Abweichung zum Mittelwert ist oft ein einfacher, aber zuverlässiger Indikator für kurzfristige positive oder negative Entwicklungen. Der gleitende Durchschnitt „glättet“ die Zeitreihe, statt starken Schwankungen mit steilen Spitzen wird eine „ruhige“ Linie dargestellt. Das ist daher oft der erste Schritt der Datenanalyse, um störende Ausreißer zu beseitigen.
Predictive Modeling
Technisch betrachtet ist Predictive Modeling etwas ganz anderes als Zeitreihenanalyse, hat jedoch das selbe Ziel: die Vorhersage zukünftiger Werte. In der Planung kann ein Zielwert meist über entsprechende Werttreiber vorhergesagt werden. Diese Werttreiber können externe Faktoren sein, wie etwa ein Wirtschaftsindikator oder Rohstoffpreise, und interne Faktoren, wie etwa Auftragslage und technologische Entwicklungen.
Auch hier müssen Daten vorliegen, z.B. ein geeigneter Marktindex für die wirtschaftliche Entwicklung und die geplante Auftragsmenge als Werttreiber für den Umsatz. In Abhängigkeit dieser Einflussfaktoren lässt sich eine Szenarioanalyse erstellen, wie
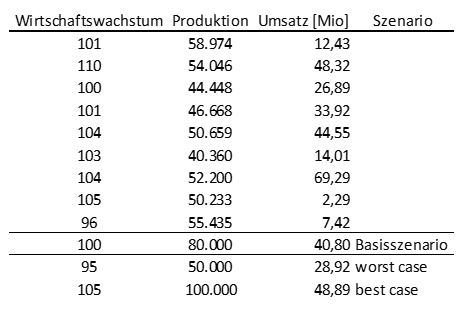
In Excel kann der erwartete Umsatz über die statistischen Analysefunktionen berechnet werden, dort ist das multiple lineare Regressionsmodell implementiert unter Daten à Datenanalyse à Regression (Wichtig: Analyse-Addin dafür aktivieren).
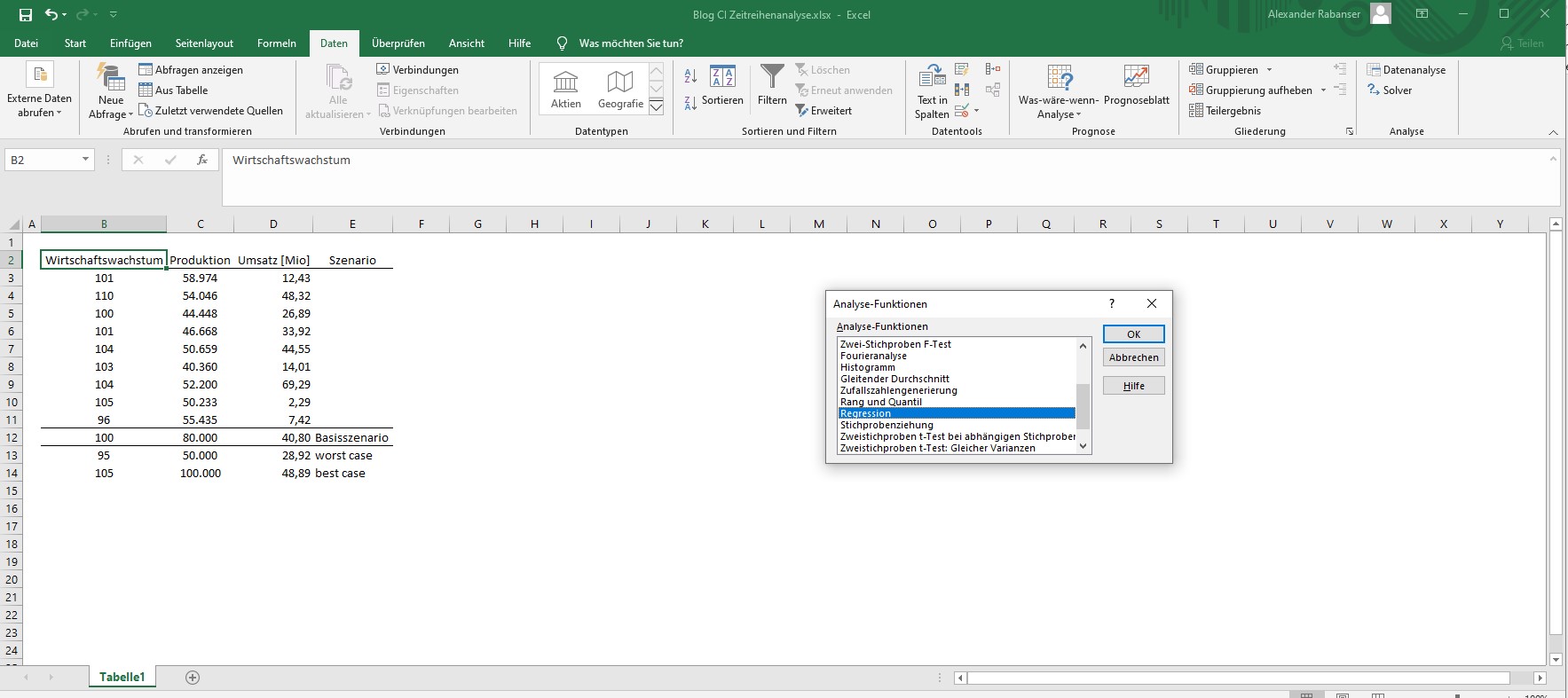
R stellt wiederum eine flexible und mächtige Erweiterung des Basismodells in Excel dar, um auch komplexere Aufgaben zu bewältigen. Auch hier gilt es, unabhängig vom Tool, das Modell zu validieren: anhand der bestehenden Daten wird ermittelt, wie genau die berechnete Vorhersage sein kann. Das ist eigentlich der wesentlichste Kern mathematischer Modellierung: abschätzen zu können, wie gut die berechneten Größen mit den realen Werten übereinstimmen werden.
Zusammenfassung
Forecasting und Predictive Modeling ist ein weites Feld mit breitem Einsatz in der Praxis. Die zum Teil komplexen mathematischen Modelle sind in Standardsoftware bereits so gut implementiert, dass Prognosen heutzutage einfach und schnell durchzuführen sind. Die Datenbasis dafür bilden historische Daten, die meist ausreichend vorhanden sind. Es lohnt sich daher ein Blick darauf zu werfen, um den Planungs- und Steuerungsprozess durch validiertes Prognosemodelle eine Stufe höher zu heben.
Weiterbildungstipp
Data Science Use Case – Forecasting & Predictive Modeling | Prognosemodelle in der Unternehmensplanung | Information und Anmeldung
Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlassen Sie uns Ihren Kommentar!